Cучасні великі мовні моделі (LLM) перетворилися на справжніх математичних монстрів, які з легкістю поглинають сотні тисяч графічних адаптерів, тисячі юнітів серверних стійок і мегавати електроенергії під час навчання. Ці “монстри” навчання народжують менших братів — “монстрів” виводу (інференсу). У відкритих LLM до категорії “середніх” потрапляють моделі з 70 мільярдами параметрів, а “великими” вважаються моделі на кілька сотень мільярдів (наприклад, DeepSeek-V3 з 671B параметрів, з яких 37B активних).
Специфіка використання LLM вимагає досить швидкої (в ідеалі, в режимі реального часу) відповіді — ніхто не захоче спілкуватися з чат-ботом із затримкою в хвилини. А якщо застосунок на базі LLM масштабується до тисяч одночасних користувачів, при великій моделі інференс вимагає значних, масивно-паралельних кластерів на GPU.
Як працює масштабування виводу LLM з використанням кількох GPU?
Для початку повернімося до витоків — математики. У 1967 році Джин Амдал виявив і сформулював просте, але непереборне обмеження зростання продуктивності при розпаралелюванні обчислень: “У випадку, коли завдання розділяється на кілька частин, сумарний час його виконання на паралельній системі не може бути меншим за час, необхідний для виконання її послідовних інструкцій”.
Математично це виражається так:
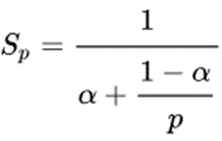
де S – це теоретичне прискорення, a – частка від загального обсягу обчислень, що припадає на послідовні операції, відповідно 1−a – частка паралельних операцій, а p – число вузлів паралельної обробки.
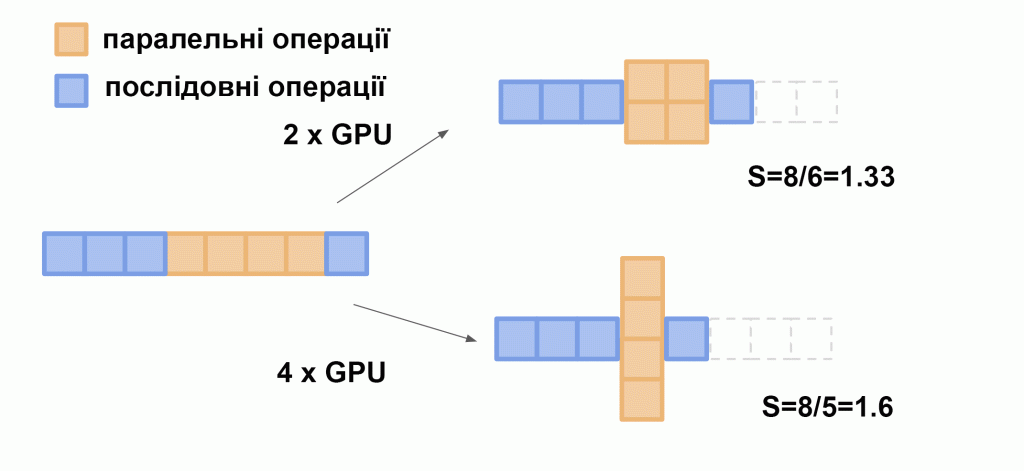
Стосовно LLM: сині кубики на схемі — це вилучення та попередня обробка нашого промпта (запиту), ініціалізація паралельних вузлів – це неминуче послідовні операції. Помаранчеві — це обчислення, які можуть виконуватися одночасно, а саме проходження одного вводу через шари моделі.
Виходячи з цього абсолютного теоретичного обмеження, ми не можемо очікувати прискорення інференсу на двох відеокартах більш ніж удвічі (навіть не наполовину, як було помилково вказано в оригіналі, а до 2× прискорення як максимум), а з урахуванням накладних витрат на зв’язок — і того менше.
Затримка, пропускна здатність та оптимізація
Базовими, фундаментальними параметрами будь-якої обчислювальної системи (інференс на GPU не є винятком) є затримка (latency) та пропускна здатність (throughput).
- Затримка — це час, необхідний для переміщення одиниці даних з однієї точки системи в іншу. У контексті інференсу LLM — це час між кожним наступним токеном, який видає наша модель.
- Пропускна здатність — це обсяг даних, які система може обробити або передати за одиницю часу. Стосовно розглянутої задачі — це кількість токенів на секунду, що видаються нашою моделлю.
В інференсі LLM у нас є певні інструменти оптимізації взаємопов’язаних параметрів пропускної здатності та затримки.
Розмір пакета (Batch Size)
За своєю суттю, у першому наближенні, LLM складаються з безлічі послідовних множень матриць. Виявляється, GPU як масивно-паралельний обчислювальний пристрій ефективно може обробляти матриці “пакетами” (batches). Час обробки великих пакетів запитів незначно зростає порівняно з поодиноким запитом.
Приклад з cnugteren.github.io/tutorial: A — це наші пакети вхідних даних, B — ваги нашої моделі. Без шкоди для продуктивності ми можемо збільшувати розмірність M матриці вхідних даних A.
Таким чином, збільшуючи (до певних розмірів) вхідний пакет, ми можемо підвищувати пропускну здатність нашого інференсу.
Квантування (Quantization)
Великі мовні моделі часто навчаються з використанням 32-бітної або 16-бітної точності. Це означає, що кожен параметр у моделі представлений або 32, або 16 бітами. 8-бітне квантування, як правило, при навчанні не використовується, оскільки призводить до нестабільних результатів і “недолугих” моделей.
Але квантування при інференсі — це законний і ефективний інструмент зменшення затримки. Якщо ми маємо систему із заданою пропускною здатністю, то, зменшуючи кількість передаваних даних, ми підвищуємо швидкість і зменшуємо затримку.
Крім того, квантування дозволяє “запихнути джина в лампу” — це можливість використання більших моделей на обмежених ресурсах GPU. 32-бітна модель вимагає 4 ГБ пам’яті для кожного мільярда параметрів, 16-бітна — 2 ГБ, 8-бітна — 1 ГБ, і таким чином LLM поміщається навіть у телефоні.
Кешування (KV Cache)
В основі LLM лежать трансформерні архітектури, а їх ключовим компонентом є механізм уваги (Attention Mechanism). У цьому механізмі для кожного токена (слова або частини слова) у послідовності обчислюються три вектори:
- Query (Q) – запит
- Key (K) – ключ
- Value (V) – значення
Коли LLM генерує текст, вона робить це авторегресійно, тобто токен за токеном. Щоразу, коли генерується новий токен, модель повинна “подивитися” на всю попередню послідовність (промпт + вже згенеровані токени), щоб визначити, який токен генерувати наступним.
Без KV Cache при генерації кожного нового токена моделі довелося б перераховувати Q, K і V вектори для всієї вже існуючої послідовності токенів. Це було б вкрай неефективно і повільно, оскільки обсяг обчислень зростав би квадратично з довжиною послідовності.
Кеш — це наш інструмент зменшення затримки та збільшення пропускної здатності.
Підсумки та виклики
Отже, ми маємо три параметри для оптимізації пропускної здатності та затримки виконання LLM-моделі: розмір пакета, квантування та кешування. Лише квантування дозволяє зменшити вимоги до апаратної складової — пам’яті GPU, і то до певних меж. Адже відповідь на питання “скільки буде 2х2” — “більше трьох, але менше п’яти” нас навряд чи влаштує. Два інші параметри вимагають збільшення “життєвого простору” — пам’яті GPU.
Грубо розмір моделі можна порахувати так:
Розмір (в ГБ) = Параметри (в мільярдах) * Розмір даних (у байтах)
Тобто Llama 2 з 13 мільярдами параметрів у точності FP32 має розмір 52 ГБ, для FP16 – 26 ГБ.
Імператив будь-якого “інференсиста”: модель повинна поміститися у VRAM. Наша Llama 2-13B своїм розміром, навіть у FP16, вже значно обмежує перелік доступних GPU. А для наших “великих пакетів” і кешів потрібен ще додатковий обсяг VRAM. Для моделі з 13 мільярдами параметрів один токен вимагає 1 МБ відеопам’яті для “ковзних” обчислень. Якщо наш запит складається зі 128 токенів (приблизно 90 англійських слів або близько 70 українських) і ми очікуємо відповідь на 128 токенів, то лише це вимагає 256 МБ простору. А якщо нас 50 осіб — 12 ГБ RTX 5070 вже закінчились навіть без завантаження моделі.
Якщо нам потрібно збільшувати пропускну здатність — тобто розмір пакета через складність нашого запиту або кількість обслуговуваних клієнтів/запитів — нам потрібна карта з величезною кількістю пам’яті або ж розділити модель між кількома GPU.
Стратегії розподілу по кількох GPU
- Повторення моделі на кількох GPU (Data Parallelism):
- Опис: Найпростіший підхід — модель повністю завантажується в кожен GPU, і система черг розподіляє вхідні запити на кожну з реплік моделей.
- Переваги: Простота реалізації.
- Недоліки: Модель повинна “влазити” цілком у пам’ять одного GPU. Нераціональність використання VRAM — в кожному GPU одні й ті ж самі ваги моделі “з’їдають” пам’ять, зменшуючи її для “великих пакетів” та кешу.
- Розбиття моделі на частини та розподіл між GPU (Model Parallelism):
- Опис: Модель розбивається на частини (наприклад, шари або частини матриць) і ці частини розподіляються між різними GPU.
- Переваги: Дозволяє використовувати моделі, які значно перевищують VRAM одного адаптера, і працювати з великими пакетами даних.
- Недоліки: Значно складніше в “математиці” та програмуванні. Має накладні витрати на зв’язок, оскільки необхідно постійно об’єднувати результати обчислень перед переходом до наступного етапу/шару.
Реалізації розподілу по кількох GPU:
- Конвеєрний паралелізм (Pipeline Parallelism): Це реалізація стратегії розбиття, де шари моделі розділяються між GPU. Це досить простий підхід, коли після того, як один пристрій завершив обробку свого фрагмента моделі, проміжні дані передаються наступному пристрою. Розбити модель вийде, а ось з паралелізмом можуть виникнути проблеми — кожен пристрій повинен чекати завершення попереднього, в результаті більшу частину часу GPU будуть простоювати, очікуючи один одного.
- Тензорний паралелізм (Tensor Parallelism): Це також реалізація стратегії розбиття. Але замість розбиття по шарах, розбиваються “внутрішньошарові” великі матриці. Оскільки матриці володіють багатьма алгебраїчними властивостями множення, притаманними звичайним числам (за винятком комутативності), то частини матриці можна обчислювати одночасно, а проміжні тензори об’єднувати для отримання повного результату. Таким чином, ми максимально завантажуємо тензорні ядра їхньою улюбленою роботою — множенням та додаванням матриць, хоча виникають деякі накладні витрати на синхронізацію тензорів.
Практика
Щоб не було нестерпно боляче дивитися на помилку “Out of Memory” — модель повинна поміщатися у VRAM. Якщо модель поміщається в пам’ять однієї карти — середовище з кількома GPU є малоефективним, оскільки витрати на зв’язок нівелюють паралелізм. Єдине виправдання — необхідність збільшення розміру пакета. У цьому випадку можна використовувати режим паралельної обробки даних на GPU, навіть більших, ніж потрібно моделі.
Якщо модель не поміщається в пам’ять одного адаптера — вибору немає, тензорний паралелізм приходить на допомогу. І тут потрібно розуміти:
- Вище обмеження Амдала не стрибнути.
- Швидше за все, затримка в “кластері” зросте.
- Зросте розмір робочого пакета, можна обслужити більше користувачів або розширити контекст.
- Екзотичні методи пакетування, використання “не того” фреймворку “не в тому місці” можуть перетворити кластер на “гарбуз”.
Побудова мульти-GPU рішення — це правильний і часто єдиний шлях, тим більше, що всі відкриті LLM-моделі підтримують тензорний паралелізм. Досить широко застосовується тензорний паралелізм у поєднанні з паралелізмом даних.
Лише повне розуміння архітектури вашого застосунку в широкому контексті дозволить правильно оцінити вимоги до апаратної частини. А реалізація вимог у “залізі” — це вже якщо й не мистецтво, то часто евристичний процес.